Раздел: Документация
0 ... 23 24 25 26 27 28 29 ... 78 ле, что будут использоваться длительное время, оправдывая усилия, направленные на аппаратную реализацию. Таким образом, хорошее понимание условий применения является важным для обоснования специализированных разработок. Одним из способов оценки степени нашего понимания вычислительных потребностей отдельной области является проверка уровня проектируемых или готовых элементов ("строительных блоков") аппаратуры. Наличие "строительных блоков" для выполнения высокоуровневых системных функций является показателем степени развитости области применения. По этой оценке техника обработки сигналов является относительно развитой областью: выпускаемые промышленностью специализированные кристаллы, такие как кристалл цифрового процессора сигналов фирмы NEC [45, 51, 60], кристалл быстрого преобразования Фурье фирмы AMI, кристалл умножителя фирмы TRW и кристалл аналого-цифрового преобразователя фирмы TRW, выполняют широкий диапазон функций на разных системных уровнях. После определения задач, которые будут выполняться на СБИС, необходимо разработать новые алгоритмы с высокой степенью параллелизма и регулярности, с малым числом внешних цепей связи и адаптированные к различным требованиям ввода-вывода [33]. Для СБИС-исполнения больше не является важной минимизация числа операций умножения, как было до сих пор; соответствующие меры сложности должны отражать противоречивые требования к площади кристалла, времени обработки и мощности [56]. Площадь кремния, необходимая для реализации алгоритма, сильно зависит от его степени регулярности [43], а требуемое время выполнения алгоритма равным образом сильно зависит от степени параллелизма. Таким образом, большинство классических проблем будут требовать новой совокупности алгоритмов. Примерами являются метод исключения Гаусса [25, 36], вычисление наибольшего общего делителя [7], рекуррентный алгоритм Винера-Левинсона [9, 40]. Для реализации алгоритмов на СБИС должна быть разработана соответствующая архитектура. Оптимизация архитектуры для выполнения узкого класса алгоритмов обычно не очень трудна, однако разработка архитектуры, позволяющей эффективно реализовать широкий класс алгоритмов, уже не тривиальная задача. Проблемой является достижение баланса противоречивых требований, таких как универсальность системы и простота программирования, гибкость и эффективность, производительность и стоимость разработки и изготовления. "Оптимальность архитектуры" зависит от технологии выполнения системы и целей, для которых она предназначена. Поэтому не следует заблуждаться относительно "универсальности" конкретного архитектурного подхода. Много интересных архитектурных идей было предложено и осуществлено; сложной задачей является точное понимание достоинств и недостатков каждого подхода при ьыборе архитектуры, удовлетворяющей данным условиям. Назначением каждой специализированной системы должно быть ее эффективное использование в законченных общих системах. Прежде чем та-160 ая специализированная система будет построена, ее параметры должны быть оценены исходя из целевого назначения системы, а после ее построения она должна быть встроена в общую систему так, чтобы ее можно было легко использовать. Например, применение кристалла сортировки требует дополнительной памяти для хранения промежуточных результатов, главной универсальной ЭВМ с программой, управляющей процессом сортировки, аппаратного и программного обеспечения связи кристалла с остальной системой. Без надлежащей аппаратуры и программного интерфейса включение заказного кристалла в законченную систему может быть задачей более сложной, чем разработка самого кристалла, и требует иного мастерства, чем при разработке кристалла. Проблема включения в систему (интегрирования), решаемая в настоящее время в основном эвристическими методами, вероятно, одна из наименее полно разработанных проблем, от решения которых зависит успех специализированного подхода. Из-за этой проблемы только небольшое число заказных кристаллов, разработанных в университетах и исследовательских лабораториях, интегрированы в законченные работающие системы. Большинство общих методов включения заказных устройств в главные системы основаны на построении интерфейса между этим устройством и стандартной шиной, такой как UNIBUS. Наличие программ стандартного интерфейса для этих шин решает только некоторые из проблем взаимодействия. Необходимы также дополнительные средства интерфейса, включая память большой емкости для хранения часто используемых данных и интерфейсный процессор для пересылки данных от адрес-ной памяти к заказной СБИС и выработки сигналов управления. 8.3. ПРОГРАММИРУЕМЫЕ СИСТОЛИЧЕСКИЕ КРИСТАЛЛЫ: АНАЛИЗ ОПЫТА В этом разделе иллюстрируются некоторые из вопросов, обсуждавшихся в разд. 8.2 на примере проекта, выполненного в университете в Карнеги-Мел-лона, к которому причастны авторы. Проект заключается в разработке и реализации программируемого систолического кристалла (ПСК) [20, 21] - однокристального специализированного микропроцессора, предназначенного для создания разнообразных систем систолической архитектуры. Кристалл ПСК является как специализированным, в том смысле, что он разработан для создания специализированных систолических систем, так и универсальным, в том смысле, что он является программируемым микропроцессором. Пример ПСК иллюстрирует также широту сферы применения специализированных устройств. Сначала дадим обзор некоторых свойств и особенностей систолических матриц, а потом опишем ПСК и осветим некоторые вопросы, возникшие в процессе его разработки. 8.3.1. Обзор систем систолической архитектуры Вычислительные задачи могут быть концептуально разбиты на два класса: вычислительно ограниченные и ограниченные по вводу-выводу. Если полное число вычислительных операций больше полного числа элементов, предназначенных для ввода и вывода, то задачи относятся к классу вычис- Рис. 8.1. Основной принцип систолической системы лительно-ограниченных; в противном случае они являются ограниченными по вводу-выводу. Например, алгоритм однократного умножения матрицы на матрицу представляет собой вычислительно ограниченную задачу, так как каждый элемент одной матрицы умножается на все элементы строки или столбца другой матрицы. С другой стороны, сложение двух матриц является задачей, ограниченной по вводу-выводу, так как полное число операций сложения не превышает полного числа элементов в обоих матрицах. Ясно, что любая попытка ускорения вычислений, ограниченных по вводу-выводу, должна быть основана на увеличении пропускной способности памяти. Пропускная способность памяти может быть увеличена или путем использования более быстродействующих элементов памяти (которые могут быть дорогостоящими), или расслоением памяти (что может создать дополнительные проблемы управления памятью). Ускорить вычисления, ограниченные по вводу-выводу, однако, часто можно относительно простым и недорогим способом: использованием систолического подхода. Систолическая система состоит из некоторого множества связанных друг с другом ячеек, каждая из которых выполняет некоторую простую операцию. Поскольку при проектировании и реализации простые регулярные структуры связи и управления имеют существенные преимущества перед сложными структурами, ячейки в систолической системе, как правило, объединены в виде систолической матрицы или систолического дерева. Информация в систолической системе передается между ячейками в конвейерном режиме, а связь с внешней средой осуществляется только через "граничные ячейки". Например, в систолической матрице только ячейки, расположенные на ее границе, могут иметь порты ввода-вывода. Основной принцип систолической архитектуры, и систолической матрицы в частности, показан на рис. 8.1. При замене простого процессорного элемента (ПЭ) матрицей ПЭ, или ячеек (по терминологии данного подраздела), вычислительная производительность может быть увеличена без увеличения пропускной способности памяти. Функция памяти на схеме рис. 8.1 аналогична сердцу: она "прокачивает" данные (а не кровь) через матрицу ячеек. Суть этого подхода состоит в том, что один раз взятые из памяти данные могут быть эффективно использованы в каждой ячейке в процессе передачи их от ячейки к ячейке вдоль матрицы. Такая организация возможна для широкого спектра задач, относящихся к классу ограниченных по вводу-выводу, где многочисленные операции выполняются над каждым элементом данных одним и тем же повторяющимся способом. 162 100 не \ Память Не больше чем 5-10еоп./с 100 не \ Па мять \ -\пз\пз\пэ \пэ\пз \пз Возможнодо 30-lOson./c Систолическая матрица Хотя прохождение данных через матрицу является синхронным на уровне алгоритма [30], машинная реализация систолического алгоритма может быть выполнена как синхронно, так и асинхронно. Там, где это возможно, синхронная схема из-за ее простоты обычно предпочтительнее. При современной технологии глобальная синхронизация возможна для всех систолических матриц, за исключением крайне больших двумерных; в некоторых случаях системы систолической архитектуры, такие как линейные матрицы, могут использоваться для расширения области применения синхронных схем даже в случае, когда задержка в линии передачи велика [19]. Возможность неоднократного использования каждого элемента введенных данных (чем обеспечивается высокая вычислительная производительность при небольшой пропускной способности памяти) является как раз одним из многих достоинств систолического подхода. Характерны и другие достоинства, такие как возможность расширения модуля, простота и регулярность потоков данных и команд управления, использование простых одинаковых ячеек, устранение глобальной передачи и разветвления и (возможно) более высокое быстродействие [33]. Далее приводится список задач (алгоритмов), доп>екающих систолическую реализацию. При перечислении этих задач преследовалась двоякая цель: отослать читателей, интересующихся применением систолического подхода к решению частных задач, к первоисточникам и показать широту применения этого подхода. 1.Обработка сигналов и изображений: а)фильтрация с конечной и бесконечной импульсными характеристиками и одномерная свертка [13, 17, 29, 31]; б)двумерная свертка и корреляция [5, 34, 37, 38, 61]; в)дискретное преобразование Фурье [29, 31]; г)интерполяция [37]; д)одно- и двумерная медианная фильтрация [18]; е)геометрические преобразования [37]. 2.Матричная арифметика: а)умножение матрицы на вектор [14, 36]; б)умножение матрицы на матрицу [36, 58]; в)приведение матриц к треугольному виду (решение систем линейных уравнений, обращение матриц) [25, 36]; г)решение треугольных систем линейных уравнений [36]; д)решение теплицевых систем линейных уравнений [9, 40]; е)QR-разложение (вычисления, связанные с методом наименьших квадратов) [6,25,28]; ж)сингулярное разложение [10]; з)решение проблемы собственных значений [11,52]; 3.Прикладные задачи невычислительного характера: а) задачи со структурами данных в виде стека и очереди [26], задачи перебора [4, 48, 53], очередей с приоритетом [42], сортировки [42, 53]; б)алгоритмы поиска на графе - определение транзитивного замыкания [27], поиск деревьев минимальной связности [3], определение компонентов связности [50]; в)геометрические алгоритмы - генерация выпускной оболочки [15]; г)распознавание языков - сравнение цепочек (символов) [22], регулярных выражений [23]; д)динамическое программирование [27] - е)алгоритмы работы с многочленами - умножение и деление многочленов [32], определение наибольшего общего делителя для многочленов [7]; ж)нахождение наибольшего общего делителя целых чисел [8]; з)операции реляционной базы данных [35, 41]; и)моделирование методом Монте-Карло [59]. 8.3.2. Программируемый систолический кристалл Из-за регулярности структуры и простоты основных компонентов стоимость разработки и практического использования систолических матриц должна быть незначительной по сравнению со стоимостью разработки других систем той же производительности. Однако это преимущество в действительности утрачивается, поскольку конкретный систолический алгоритм обычно разрабатывается для конкретного применения и, следовательно, стоимость разработки не может быть компенсирована выпуском большого числа элементов, что характерно для производства универсальных процессоров. Поэтому необходимо обсудить несколько вариантов достижения компромисса между универсальностью и производительностью. При решении прикладных задач с жесткими требованиями к производительности, таких как обработка сигналов, часто оправдано использование полностью заказных ИС, в то время как в других областях можно обойтись существующими более гибкими средствами. Разработанные систолические процессоры перекрывают спектр этих областей применения. Первыми реализованы [22, 38] были полностью заказные устройства, ориентированные на конкретный алгоритм, например кристалл коррелятора фирмы GEC [17]. Средней степенью гибкости обладают систолический процессор фирмы ESL [5, 61] и готовящееся к выпуску семейство кристаллов фирмы ESL для выполнения операций матричного умножения с плавающей запятой; они программируются на широкий перечень задач обработки сигналов. Практически универсальным процессором является систолическая матрица испытательного стенда военно-морского центра океанских систем (США) [12, 54, 55], которая собрана из микропроцессоров общего назначения и обеспечивает одно- и двумерную структуру связи процессорных элементов (ячеек). Другим гибким подходом, использованным при проектировании ИСК, является разработка "строительных блоков" широкого применения. В преддверии развития автоматизированных систем проектирования, которые могли бы создать эффективные принципиальные схемы на основе математических описаний высокого уровня, полезно иметь некоторые средства компоновки систолических матриц различных типов и размеров 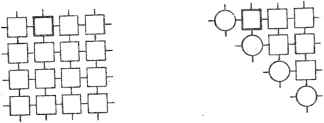 Рис. 8.2. Кристалл "строительного блока" в различных систолических матрицах из небольшого числа "строительных блоков". Чтобы обеспечивалось выполнение множества алгоритмов, такие средства должны обладать программи-руемостью как индивидуальных ячеек, так и связи между ними. Отметим, что свойство перестраиваемости конфигурации требуется только на этапе разработки алгоритма, а не в течение времени его исполнения, так как структура систолической матрицы и поведение ее ячеек мало изменяются в процессе вычислений. Одним из путей обеспечения этой гибкости является использование программируемого однокристального процессора, как изображено на рис. 8.2. Если каждый кристалл представляет собой индивидуальную программируемую ячейку, то много кристаллов могут быть объединены на уровне платы (или в будущем - на одной полупроводниковой пластине) для построения матрицы систолической структуры. Это решение хорошо учитывает современную технологию, так как кристаллы одновременно являются достаточно большими и достаточно малыми для удобною расположения на них процессора: достаточно большими, поскольку процессор может целиком умещаться на одном кристалле, благодаря чему отсутствуют затраты на размещение и реализацию линий связи, присущие многокристальной ИС; достаточно малыми, поскольку даже при некотором увеличении плот- 165 0 ... 23 24 25 26 27 28 29 ... 78 |












