Вы находитесь в разделе Типовых решений систем безопасности
Мультимодальная биометрия -перспективное решение. Объединение алгоритмов для повышения надежности распознавания человекаА.Б. Мурынин
Д.В. Ковков В.В. Лобанцов К.А. Маковкин И.А. Матвеев Д.Д. Десятников В.Я. Чучупал Унимодальные или мультимодальные? За последние годы появилось большое количество унимодальных систем распознавания человека по отпечаткам пальцев, голосу, термограмме лица, рисунку вен ладони, запаху и другим данным, но лишь немногие технологии распознавания достигают эксплуатационных характеристик, позволяющих говорить о практическом применении в режиме идентификации. Биометрия предлагает выделение уникальных характеристик, присущих человеку, что во множественных случаях является самым удобным и надежным решением проблемы распознавания. Разработка систем контроля доступа не ограничивается созданием оптимизированных алгоритмов распознавания и их реализацией в программно-аппаратных комплексах. Система в целом должна отвечать ряду практических требований. Например, системы распознавания по радужке глаза или по отпечаткам пальцев неудобны на практике, так как предъявляют жесткие требования к порядку сканирования биометрических характеристик. Кроме того, пользователи систем распознавания по отпечаткам пальцев обеспокоены гигиеничностью цикла, а систем распознавания по радужке -жесткими требованиями к движениям и степени видимости некоторых значимых частей глаза. Способы распознавания по лицу и голосу имеют ощутимое преимущество: видеозахват и аудиозапись не требуют физического контакта пользователя с системой и тщательного позиционирования перед регистрирующим сенсором. Существенные недостатки известных унимодальных биометрических систем: увеличение сложности вычислений, падение качества распознавания при росте количества распознаваемых людей, относительно слабая защищенность против фальсификаций. Мультимодальные биометрические системы, имеют дело с биометрическими параметрами человека разной природы, позволяя создать его более информативную и защищенную биометрическую "подпись". Такая смешанная или мультимодальная биометрия - наиболее перспективное решение ближайшего будущего и один из самых привлекательных способов повышения эфф. биометрических систем. Основные первопричины слабого развития смешанной биометрии:
Типы смешивания технологий Выделяют три типа смешивания технологий, перечислим их в порядке роста эффективности:
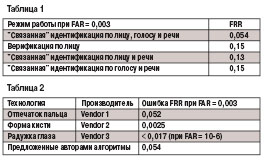
Разработанные и апробированные методы объединения биометрических технологий на уровне мер сходства экспериментально продемонстрировали, например, что комплексирование технологий двухмерного и трехмерного распознавания лица в режиме регистрации приводит к уменьшению ошибки первого рода фактически в три раза по сравнению с унимодальной технологией двухмерного распознавания лица при фиксированной ошибке второго рода. Ряд других экспериментов подтвердил, что объединение технологий распознавания лица и отпечатков пальцев в режиме верификации снижает норму равной ошибки EER (значение, при котором ошибки первого и второго рода равны) на 1 %, что,, уменьшает на 20-50% ошибку первого рода (FRR) в зависимости от выбранной стратегии - выставленного значения порога принятия решения. Комплекс для устойчивого распознавания человека Одна из возможных комбинаций биометрических признаков - сочетание распознавания по лицу и голосу. Предлагаемая нами система реализует второй уровень объединения. изучим требования, выдвинутые на этапе проектирования, основу и сценарий работы системы в целом, и некоторые применяемые алгоритмы распознавания и подсистему интегрированного принятия решения. Требования к системе Приступая к разработке комплекса алгоритмов, мы выдвинули следующие требования к прототипу системы:
Комплекс устойчивого распознавания человека состоит из аппаратных средств и программного обеспечения, позволяющих производить видеозахват пар изображений, запись аудиоданных в режиме стерео, выдавать команды для диалога с пользователем и обрабатывать данные всех информационных каналов для принятия окончательного совместного решения по распознаванию человека. Два канала аудио решают задачу подавления шумов в речевом сигнале. Стереоскопическое видео дает принцип. возможность надежно обнаруживать на любом фоне лицо человека как трехмерный объект и обеспечивает дополнительную защиту от попыток взлома с помощью фотографии или видеофильма. Перспективно также использование трехмерной информации как дополнительного канала распознавания. Сценарий работы системы Схема идентификации следующая: обнаружение присутствия человека - интенсивный поиск лица - запрос речевых данных - распознавание речи -составление списка связанных кандидатов - отслеживание лица - совместное распознавание черт лица и голоса. Общий сценарий работы системы таков: после запуска и инициализации она переходит в рабочий режим (идентификации), реализующий вычислительно простой цикл, который при некотором условии активирует процедуры сканирования (захвата) видео- и аудиоданных человека и последующего их распознавания. В зависимости от настроек системы условием начала захвата может быть обнаружение одного или нескольких признаков:
Если нет жесткой необходимости в соблюдении условия отсутствия физического контакта пользователя и системы, возможно подключение клавиатуры и запуск сканирования по нажатию клавиши. Систему можно дополнить "классическим" ПИН-кодом (персональным идентификационным номером), введенным с клавиатуры, и перейти от задачи связанной идентификации к простой верификации. В цикле регистрации использовались вычислительно сложные, но более надежные и устойчивые методы поиска лица на изображении и детектирования речи. Полученные результаты далее применялись для выделения черт лица, речевых компонент и построения шаблонов по этой биометрической информации. Сочетание нескольких "быстрых" методов для обнаружения присутствия человека с "медленными", но надежными методами обработки захваченных данных давало системе значительную гибкость. В случае успешной регистрации обоих типов биометрии выполнялась двухступенчатая процедура идентификации, описанная выше. В режиме идентификации человек, подходящий к месту контроля, должен произвести следующие действия:
Здесь и далее термином "ПИН" называется последовательность из пяти цифр. Она уникальна в рамках собранной базы для каждого человека, что позволяет производить распознавание не только по характеристикам голоса, но и по содержанию произнесенной фразы. Применяемые алгоритмы Алгоритмы, применяемые в системе, можно разделить по подсистемам обработки и распознавания аудио- и видеоданных и принятия совместного решения. Первая подсистема состоит из модулей детектора речи, распознавания речи и распознавания голоса, вторая - из модулей обнаружения изменений сцены и трехмерных объектов заданной геометрии, поиска лица и уточнения положения его частей на изображении и распознавания лица. Распознавание речи в системе реализовывалось на базе небольшого конечного словаря команд (цифры, вспомогательные слова на русском и английском языках). Оно производилось в том числе и при помощи СММ (скрытые марковские модели) и трехмерных самоорганизующихся карт для кепстральных коэффициентов (MFCC). Распознавание голоса осуществлялось посредством оценки его уникальных характеристик во время произнесения ПИН и сравнения их с характеристиками голоса эталона с учетом произносимого ПИН. Распознавание лица производилось в том числе и на основе разложения изображений лица и его черт в подпространствах главных компонент. В системе были использованы основные усовершенствования данного подхода, включая дискриминантный анализ Фишера и сканирование локальных окрестностей. Подсистема интегрированного принятия решения Проблема построения интегрированного решающего правила по разнородным признакам многократно обсуждалась как с теоретических, так и с прикладных позиций. Эксперименты показали, что ошибки распознавания по голосу и изображениям лица слабо.Коррелируют м. собой и поэтому возможно создание совместного решающего правила, позволяющего улучшить результаты распознавания. В нашем случае решающее правило было построено как линейный классификатор, разделяющий сравнение на два класса: "сравнение эталонов одного человека" и "сравнение эталонов разных людей". Поскольку основные показатели качества систем контроля доступа - процент неверного отказа в доступе зарегистрированному пользователю (FRR, ошибка первого рода) и процент пропуска нарушителя (FAR, ошибка второго рода), то классификатор строился чтобы минимизировать относительное количество ошибок первого рода при заданном фиксированном относительном уровне ошибок второго рода, равном 0,003 на обучающей выборке. Попытки применить другие типы функций разделения (например, квадратичную) не дали статистически значимых улучшений (рис. 1). Тестовая база данных Для обучения и тестирования алгоритмов распознавания, и выбора решающего правила нами была собрана масштабная экспериментальная тестовая база данных - синхронные записи стереовидео изображений и стереофонического звука. Особенности работы прототипа системы При создании тестовой БД и последующем тестировании алгоритмов мы стремились учесть некоторые особенности работы прототипа системы:
Процедура сбора БД Для учета указанных особенностей работы системы мы соответствующим образом построили процедуру сбора экспериментальных данных:
Обучающая и тестовая БД
Для обучения классификатора использовалась БД, состоящая из 700 сессий синхронных записей голоса и изображений лица, принадлежащих 300 субъектам. Для выделения свойств распознавания по характеристикам голоса каждый из зарегистрированных субъектов произносил не только свой ПИН, но и один или несколько чужих, а алгоритм распознавания голоса при сравнении разных людей оценивал сходство "чужих" ПИН-фраз. Создание обучающей БД производилось так, что для каждого тестового субъекта существовало несколько других, произносивших его ПИН. Тестирование Были проведены предобработка БД и последующее тестирование отдельных модулей распознавания лица, голоса и речи, и интегрированной системы. Предобработка БД изображений лиц Тестирование алгоритмов распознавания лица включало следующие основные этапы работы с БД изображений лиц:
Основной операцией предобработки данных было проведение полуавтоматической разметки лиц на видеопоследовательностях изображений для создания качественных эталонов. Размечаемыми чертами являлись положения центров зрачков глаз и рта с субпиксельной точностью. Под термином полуавтоматическая разметка понимается участие оператора в проведении разметки на одном из начальных кадров, просмотр и исправление результатов автоматической разметки на остальных кадрах. Обуч. и настройка алгоритмов заключалась в построении пространства главных компонент для областей лица и глаз в разных ракурсах на обучающей выборке. Тестирование модулей распознавания лица При тестировании алгоритмов распознавания лица на тестовой БД выполнялись следующие операции:
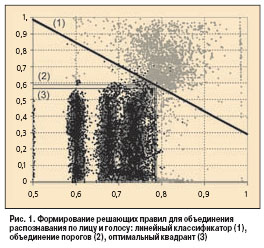
Результаты тестирования интегрированного решающего правила Чтобы провести тестирование идентификации с учетом двух существующих типов сравнений (сравнения шаблонов одного человека и разных людей) были выделены сессии не менее 700 разных субъектов, содержавшие произнесение чужого ПИН друг для друга. Распознавание речи производилось с учетом информации о сценарии записи, исходя из которой выделялся звуковой фрагмент, соответствующий одному из произнесений ПИН. Полученная гипотеза передавалась на распознаватели голоса и лица. Результат формировался в виде точки двумерного пространства решений. Пространство решений было разделено прямой на базе оптимального линейного разделения классов, соответствующих положительной идентификации человека и отказу в идентификации. Решающее правило для мультимодальной системы распознавания формировалось на основе обучающей выборки из данных не менее 300 человек. Для каждого шаблона на базе информации об обучающем множестве производилось сравнение по лицу и голосу с эталоном, соответствующим собственному и чужому ПИН. формировались одинаковые по размеру наборы точек двух классов на плоскости решения. На рис. 1 первый из них отображен множеством серых точек, второй - множеством черных точек, а оси абсцисс и ординат задают степень сходства лица и голоса соответственно. Были опробованы следующие методы классификации, каждый из которых имеет две степени свободы:
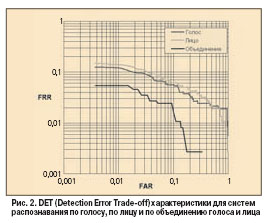
Оптимальность разделения понимается в смысле минимизации доли ошибок первого рода. Наилучшим главным правилом при FAR = 0,003 оказалось линейное разделение (FRR = 0,054), фактически столь же хорошим был квадрант (FRR = 0,061). Значительно худший результат давало объединение порогов (FRR = 0,1 37), он иллюстрирует приведенный выше тезис о том, что объединение бинарных решений менее эффективно, чем построение решающего правила на основании известных мер сходства. Объединенное решение, сформированное на базе оптимального линейного разделения плоскости решений для обучающего множества, показало существенное сокращение уровня ошибок, которое можно видеть на рис. 2. В табл. 1 даны точности распознавания различных комбинаций биометрических методов при заданном значении FAR. Полученные результаты пишут об эфф. предложенного метода "связанной" идентификации. Применение этого метода к совокупности всех использованных признаков, а именно лица, голоса и речи, позволило уменьшить вероятность ошибок первого рода примерно в 3 раза по сравнению со случаями унимодального распознавания только по лицу или по голосу. Следует отметить, что эффективность "связанной" идентификации по лицу и речи (без использования голоса) сопоставима с эффективностью верификации по лицу. Сравнение точности интегрированной системы с другими биометрическими технологиями, которые продемонстрировали хорошие результаты в тесте CESG Test 2001, приведено в табл. 2. Представленные данные пишут о том, что метод "связанной" идентификации сопоставим по эфф. с современными подходами на базе других биометрических технологий. Имея в виду указанные выше функциональные преимущества, а именно отсутствие физического контакта с системой, уменьшение проблем при масштабировании, можно говорить о перспективности применения предложенного подхода. Заключение Предложенный нами метод "связанной" идентификации показал достаточно высокую надежность при работе с базой биометрических данных не менее полутора тысяч человек. Использование этого метода позволило снизить примерно в три раза уровень ошибок первого рода при фиксированном уровне ошибок второго рода. В качестве базовых алгоритмов распознавания по каждому отдельному признаку (лицу, голосу, речи) нами были взяты популярные алгоритмы, которые уже использовались ранее как авторами данной работы, так и другими исследователями. Известно, что надежность алгоритмов идентификации снижается при увеличении количества зарегистрированных пользователей. Как показано в данной аналитической статье, предложенный метод является эффективным средством для решения этой проблемы.Проведенные исследования позволили оценивать возможности мультимодальной биометрической системы и показать, что она можетдостичь достаточно высокой точности автоматического распознавания личности. Читайте далее:  Распознавание человека по радужке Интернет меняет принципы СКУД Компания "Семь Печатей" на данный момент. Гармония в движении Замки и доводчики Abloy: хорошие новости от старого знакомого Металлообнаружитель "Признак" на службе безопасности Мультимодальная биометрия -перспективное решение. Объединение алгоритмов для повышения надежности ра Новинки Proximity- и Smart-технологии в системах доступа Новые контроллеры СКУД от HID в России! Автоматизированная пapкoвoчнaя cиcтeмa GrifonTer Park Особенности программного обеспечения для СКУД разного масштаба Пластиковые карты и методы их персонализации (Часть I) Программно-аппаратный комплекс CANTEC Регламент на системы комплексной безопасности Рынок СКУД Рынок СКУД один из наиболее динамичных рынков Распознавание человека по радужке Интернет меняет принципы СКУД Компания "Семь Печатей" на данный момент. Гармония в движении Замки и доводчики Abloy: хорошие новости от старого знакомого Металлообнаружитель "Признак" на службе безопасности Мультимодальная биометрия -перспективное решение. Объединение алгоритмов для повышения надежности ра Новинки Proximity- и Smart-технологии в системах доступа Новые контроллеры СКУД от HID в России! Автоматизированная пapкoвoчнaя cиcтeмa GrifonTer Park Особенности программного обеспечения для СКУД разного масштаба Пластиковые карты и методы их персонализации (Часть I) Программно-аппаратный комплекс CANTEC Регламент на системы комплексной безопасности Рынок СКУД Рынок СКУД один из наиболее динамичных рынков
|