Раздел: Документация
0 ... 18 19 20 21 22 23 24 ... 78 няется. В гл. 11 рассматриваются важные вопросы отображения вычислительных задач большой размерности на ограниченные структуры процессорных элементов и дается обзор современных подходов. Наиболее эффективные методы декомпозиции требуют использования нескольких процессорных модулей. В этом случае весьма желательны программируемость и гибкость управления матрицей. Эта область исследований только развивается и содержит еще много нерешенных проблем. В алгоритмах, подходящих для реализации на СБИС, используются параллельность, присущая как прикладным задачам, так и архитектуре вычисления при соблюдении локальности (т.е. короткие линии связи) и сбалансированного распределения работ (по процессорам). Для описания СБИС-алгоритма требуется точная система обозначений, позволяющая отразить его естественный параллелизм. Абстракция вида "функции" и "состояния" должны позволить изменять состояние машины способом, свободным от побочных эффектов. Кроме того, спецификация потока данных в локальных синхронизируемых алгоритмах требует адекватного механизма связи. К тому же система обозначений должна быть проблемно ориентирована (т.е. адаптирована на нужный уровень абстракции процесса проектирования). Важным достоинством точных описаний является то, что они могут быть исполнены на некотором вычислительном устройстве, и это свойство обеспечивает проблемно ориентированную диагностику прототипа СБИС-алгоритма. В гл. 12 предложена исполнимая спецификация алгоритмов для СБИС в духе функционального npoi раммирования. Она основана на вычислительной концепции "пространства данных", введенной автором несколько лет тому назад в виде формальной модели абстрактных машин. Пространство данных определяется в терминах ансамбля функций довольно общего вида, ассоциативной памяти и ансамбля функций, выражающих определение "процессора". Система обозначений позволяет определять рекурсивные типы и является аппликативной в том смысле, что в процессе вычисления переходов из состояния в состояние и самих состояний отсутствуют побочные эффекты, влияющие на состояния. Для выражения локальной синхронизации введены синтаксические понятия: "подпространства" в виде отдельных вычислительных подструктур и "синхронизируемые типы", которые обеспечивают потоковый механизм связи. Предлагаемая система обозначений была реализована и использована в качестве средства дальнейшей разработки исполняемой спецификации алгоритмов и тестирования на высоком уровне в различных прикладных задачах, решаемых с помощью СБИС. В гл. 13 вводится иерархическая методология точного описания и проверки систем на СБИС. В ней предлагается представление алгоритмов системой пространственно-временных рекуррентных соотношений с указанной семантикой (семантикой с фиксированной запятой). Диапазон применения языка широк, и одни и те же обозначения используются для систем, начиная от уровня транзисторов и кончая уровнем взаимодействующих процессов. Другими словами, предлагаемое представление может служить и как система параллельного программирования, если рассматриваются 130 взаимодействующие процессы, и как система описания аппаратурной реализации при исследовании интегральных схем. Цифровая обработка сигналов основана на фундаментальной математической теории, используемой в процессе разработки программ. Благодаря центральной роли понятий сигнала и системы хорошо структурированная программа обработки сигналов организована как совокупность "сигналов" и "систем". В гл. 14 рассматривается три представления дискретно-временных сигналов в программах. В частности, вместе с представлением абстрактных сигналов вводится новый язык представления сигналов - SRL, который удовлетворяет множеству желаемых критериев представления сигналов. Имеется обширная литература по проектированию цифровых фильтров для систем обработки сигналов. Недавно возобновился интерес к изучению структур фильтров с целью выявления параллелизма. В гл. 15 предлагается подход, использующий графы предшествования для систематического распознавания потенциально достижимого максимального параллелизма данной структуры. В дополнение к высокой пропускной способности, получаемой путем организации параллелизма и многоуровневого конвейера, высокое качество числовых характеристик достигается с помощью особых ортогональных арифметических операций. Подход демонстрируется созданием модуля CORDIC с двойным конвейером: глобальным между процессорными элементами (ПЭ) и локальным на уровне разрядов. Применение этого модуля для организации ортогональных фильтров или волновых матриц позволяет получить максимальную пропускную способность. Большинство подходов в обработке сигналов приводит к интенсивным арифметическим вычислениям. Поэтому для решения специальных прикладных задач важно уметь выбирать соответствующие арифметические устройства. В гл. 16 дается широкий обзор арифметических устройств различной архитектуры для цифровой обработки сигналов на СБИС и проводится их сравнение по разным параметрам. Глава предоставляет необходимые сведения, позволяющие выбрать нужное устройство из разработанных к настоящему времени вариантов. 7 СБИС-ОБРАБОТКА СИГНАЛОВ: ОТ ТРАНСВЕРСАЛЬНОЙ ФИЛЬТРАЦИИ К ПАРАЛЛЕЛЬНОЙ ОБРАБОТКЕ С. Гун1 7.1. ВВЕДЕНИЕ Успехи микроэлектронной технологии СБИС и появление методологии автоматизации проектирования привели к революционным изменениям в 1 Университет Южной Калифорнии, Лос-Анджелес, Калифорния. области обработки сигналов. При этом область СБИС-обработки сигналов естественно оказалась в фокусе будущих технологических исследований. Чтобы перекинуть мост от теории и алгоритмов обработки сигналов к архитектуре процессоров и их реализации на СБИС, очень важно понимать как требования современной обработки сигналов к вычислительным системам, так и ограничения со стороны технологии СБИС. Это потребует взаимного обогащения теории обработки сигналов и теории разработки и проектирования вычислителей. С одной стороны, постоянно растущие требования к эффективности и сложности алгоритмов и обработке сигналов в реальном масштабе времени указывают на потребность в огромной вычислительной мощности как по объему, так и по быстродействию. Наличие дешевых, компактных и быстродействующих СБИС делают высокоскоростную параллельную обработку данных большого объема практичной и экономичной [1]. Это позволяет достичь сверхвысокой производительности и предвещает технологический рывок в области обработки сигналов в реальном масштабе времени. С другой стороны, совершенно очевидно, что потенциальные возможности СБИС могут быть использованы только при условии четкого представления области их применения. Поэтому следует отметить, что традиционные методы разработки архитектуры вычислителей не совсем подходят для проектирования высокопараллельных СБИС-процессоров. Например, высокая стоимость разработки проекта наводит на мысль о целесообразности использования структуры из повторяющихся модулей. Однако поскольку главной технологической трудностью является обеспечение соединений в СБИС-системах, что связано с увеличением занимаемого пространства, мощности и затрат времени, то приходится ограничиваться только локальными связями [1]. Традиционный способ построения параллельных вычислителей и языков также не подходит для системы обработки сигналов в реальном масштабе времени [18] из-за большого числа вспомогательных операций, связанных с распределением вычислительных ресурсов и препятствующих повышению производительности. В многопроцессорных системах на СБИС необходимо использовать локальные связи, чтобы уменьшить взаимную зависимость процессоров и задержки, вносимые чрезмерно длинными соединениями. Эта вынужденная локальность препятствует введению глобальной передачи данных и глобальной синхронизации. Получающиеся в результате распределенное управление, локальные связи и управляемые данными вычисления становятся все более и более привлекательными как по аппаратному, так и программному обеспечению. Такие соображения привели к разработке нескольких специализированных устройств обработки сигналов с архитектурой, ориентированной на исполнение в виде СБИС. Эта глава посвящена алгоритмическому анализу, лежащему в основе развития архитектуры таких устройств, и компромиссам, связанным с их реализацией на СБИС. В разд. 7.2 дается обзор отдельных схем обработки сигналов, допускающих СБИС-исполнение, включая трансверсальный фильтр, систолическую матрицу, потоковый процессор и волновую матрицу. 132 В разд. 7.3 рассматривается методология нисходящего проектирования и исследуется отображение алгоритмов в архитектуру вычислителей. Далее иллюстрируется развитие принципов проектирования от основной канонической формы БИХ-фильтра [2] к систолической и волновой процессорной матрицам. В разд. 7.4 исследуется обработка с использованием двумерной волновой процессорной матрицы. На основе понятия волнового фронта вычислений демонстрируется такой подход к проектированию, который позволяет тесно координировать разработку языка и архитектуры. 7.2. МАТРИЧНЫЕ СБИС-ПРОЦЕССОРЫ ДЛЯ ОБРАБОТКИ СИГНАЛОВ 7.2.1. Трансверсальная фильтрация Кроме БПФ, возможно, самым полезным в технике цифровой обработки сигналов является цифровая КИХ- и БИХ-фильтрация. КИХ-фильтр с передаточной функцией м H(z)= 5>,2-< часто реализуется на линии задержки с отводами, как показано на рис. 7.1, и иногда называется трансверсальным фильтром [3]. Следует отметить, что эта обычная схема требует глобальных связей (для операций суммирования) . Однако при разработке СБИС отдается предпочтете модульным системам с локальными связями, такими как в систолических [5, 6] или волновых матрицах [7]. 7.2.2. Систолические матрицы Систолическая система представляет собой сеть процессоров, которые работают синхронно и передают данные сквозь систему [6]. Например, как показано в [5], несколько основных процессорных элементов (ПЭ), выполняющих операцию "скалярное произведение" (У*- Y+A*B), может быть локально соединено для выполнения КИХ-фильтрации способом, подобным трансверсальной фильтрации. Для эффективного выполнения мат- 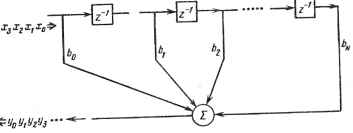 Рис. 7.1. Трансверсальный фильтр на основе линии задержки с отводами ричного умножения, /.-разложения и других матричных операций может быть построена двумерная систолическая матрица процессорных элементов. Основной принцип систолической обработки заключается в том, что все данные во время их регулярной и ритмичной передачи через матрицу могут быть эффективно обработаны во всех ПЭ. Важными свойствами систолической матрицы являются модульность, регулярность, локальность связей, высокая степень конвейеризации вычислений и высокая синхронность параллельной обработки. Такая матрица не требует управления, совмещает операции ввода-вывода с вычислениями, и, следовательно, ускорение вычислений может быть достигнуто без увеличения требований к пропускной способности ввода-вывода [6]. Однако имеется несколько спорных проблем, касающихся систолических матриц. Во-первых, систолические матрицы требуют глобальной синхронизации (т.е. глобального распределения синхронизирующих импульсов). Это может привести к расфазировке синхросигналов в системах с большим числом СБИС. К тому же в полностью систолических системах время выполнения операций стараются делать одинаковым. Например, для систолической матрицы, выполняющей операцию свертки [5], локальная передача данных длится то же время, что и операция умножения-сложения (т.е. один полный такт). Это часто приводит к излишним затратам процессорного времени, поскольку практически необходимое время передачи данных всегда незначительно. Другим важным вопросом являются описание алгоритма на языке параллельной обработки и программирование сложных потоков данных. Названные проблемы служат причиной пересмотра хорошо известных асинхронных схем, обычно применяемых в ЭВМ с потоковым управлением. 7.2.3. Потоковая многопроцессорная система Потоковый мультипроцессор [8, 9] представляет собой асинхронный управляемый данными мультипроцессор, который работает по программе, выраженной через систему обозначений потока данных. Так как выполнение команд такого процессора ведется под управлением данных (порядок исполнения команд зависит только от имеющихся в распоряжении операндов и требуемых ресурсов), независимые команды могут выполняться одновременно, не препятствуя друг другу. Основными преимуществами потоковых мультипроцессоров по сравнению с обычными являются простое представление параллельных процессов, относительная независимость процессорных элементов, широкое использование конвейерной организации, ограниченное использование централизованного управления и глобальной памяти. Например, в [9] показано, что мультипроцессор с потоковым управлением может выполнить умножение матриц за время, пропорциональное 0(N), т. е. так же, как и систолическая матрица. Однако для универсальных потоковых мультипроцессоров сложными проблемами являются реализация соединений процессоров и конфликты при одновременном доступе к памяти 134 го1 Эти проблемы могут быть решены, если при обработке с потоковым уязвлением использовать идеи локальности и регулярности [7], что фактически приведет к концепции волновой матричной обработки. 7.2.4. Волновая процессорная матрица Волновая матрица представляет собой программируемый матричный процессор, который сочетает в себе отличительные черты потоковых процессоров (асинхронность и управляемость данными) и систолических матриц (регулярность, модульность и локальность связей). Для матричных процессоров на СБИС желательно иметь эффективный язык программирования с использованием пространственно-временных понятий. Потребность в мощном описательном инструменте особенно ощутима, когда встречаются более сложные алгоритмы, такие как алгоритмы нахождения собственных и сингулярных значений матриц. Хотя первоначальная систолическая концепция основана на движении данных между процессорами в матрице, это, к сожалению, еще не приводит автоматически к простому языковому описанию. В противоположность этому введение понятия "волновая обработка" дает более простые описания движения данных в одномерных и двумерных матрицах. Точнее, в волновых моделях используются асинхронность и управляемость данными потоковых машин и локальность и регулярность систолических матриц. Это приводит к разработке языка матричного потока данных (matrix data flow language - MDFL) [7], предназначенного для описания сложных последовательностей взаимодействий и движения данных. Некоторые примеры будут даны в последующих разделах. 7.3. ОТ АНАЛИЗА АЛГОРИТМОВ К РАЗРАБОТКЕ АРХИТЕКТУРЫ Цикл разработки СБИС может включать в себя следующие этапы исследования: 1 - спецификацию применения - описание требований области применения, 2 - теории и алгоритма, 3 - структуры вычислителя и языка, 4 - архитектуры процессора, 5 - автоматизированное проектирование, компоновку и изготовление, 6 - размещение кристаллов в системе. Поэтому нисходящее проектирование должно начинаться с полного понимания сути перечисленных этапов разработки. 7.3.1. Анализ рекурсивных алгоритмов Говорят, что рекурсивный алгоритм является локальным, если разность пространственных индексов в двух последовательных рекурсиях находится в заданных пределах. В противном случае говорят, что алгоритм глобальный; для такого алгоритма будет всегда требоваться вычислительная структура с глобальными связями. Типичным примером рекурсивного алгоритма глобального типа является алгоритм вычисления БПФ. Принцип БПФ (при прореживании во времени) основан на последовательном разделении данных, скажем {*(/)}, счетными и нечетными индексами. Эта схема разделения будет приводить к глобальной 135 0 ... 18 19 20 21 22 23 24 ... 78 |












