Раздел: Документация
0 ... 69 70 71 72 73 74 75 ... 78 Связной процессор Рис. 25.10. Принцип построения машины базы данных изображения Распределитель запросов Сеть управления базой данных 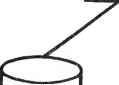 Модули данных  • • •  Сеть соединений с разделением ресурсов  "Г  Л • • •  л Кристаллы СбИС распределяется также и между модулями памяти. Сеть соединений с разделением ресурсов связывает эти ресурсы с запоминающей средой. При организации реляционной базы данных будут использоваться общие операторы для фильтрации данных, проектирования, объединения и других операций. Некоторые из операторов базы данных на СБИС приведены в табл. 25.1. 25.5. РАСПРЕДЕЛЕНИЕ РЕСУРСОВ В общем случае через сеть соединений передаются запросы от некоторого множества источников к множеству пунктов назначения (они могут совпадать друг с другом). В режиме разделения ресурсов пунктами назначения являются идентичные ресурсы, такие как специализированные кристаллы СБИС, на которые и могут направляться запросы или задания. В этом случае работы, инициированные в процессорах-источниках, могут пересылаться в любой из свободных ресурсов данного типа в месте приема. Именно это важное обстоятельство отличает разделение ресурсов от адресации. Поскольку система работает непрерывно, запросы от процессоров-источников могут поступать в случайные моменты времени. В любое время часть процессоров может выставлять запросы, а часть ресурсов может быть свободной. Функцией планировщика и является такое распределение запросов, при котором к процессорам было бы подключено максимальное количество ресурсов. 436 Самые ранние работы по сетям распределения ресурсов были реализованы с использованием централизованного управления. Например, в универсальной шине используется принцип разделения времени при подключении устройств ввода-вывода к центральному процессору. Многопроцессорная система мини-ЭВМ PLURIBUS содержала множество разделяемых во времени шин. В системе C.mmp использовался коммутатор, хотя система в основном работала в режиме адресации. Одно- или многошинный подход-источник узких мест, но и наименее дорогостоящий принцип. При наличии коммутатора сеть дорогостоящая, но при этом минимальна степень блокировок. Компромиссным вариантом является использование сети меньшей стоимости, чем при наличии коммутатора, но имеющей меньшую вероятность блокировок, чем одношинная система. Это было исследовано при рассмотрении баньяновской (Banyan) сети. Предложена древовидная структура, помогающая планировщику в распределении ресурсов. Древовидная структура имеет задержку 0(log2 п) при выборе свободного ресурса (п - общее количество ресурсов). Исследованные ранее алгоритмы планирования являются централизованными и ориентированы на использование адресных сетей соединений. В худшем случае сложность алгоритма распределения п запрашивающих процессоров по п ресурсам равна 0(n log2 п). Эта сложность зависит от числа запрашивающих процессоров. Подход практичен при малом п или при не слишком высокой частоте поступления запросов. Решением, которое устраняет последовательное распределение запросов, является разрешение распространения запросов без каких бы-то ни было тэгов назначения и перенесение на сеть ответственности за маршрутизацию максимального числа запросов к свободным ресурсам. Таким образом, "интеллект распределения" рассредоточивается по сети соединений. Этот подход позволяет одновременно передавать множество запросов. Такую сеть называют сетью соединений с разделением ресурсов. Сети "Омега" и "Обобщенный куб" принадлежат к классу сетей, в которых задержка от источника до любого достижимого приемника пропорциональна логарифму числа источников. Основным элементом этих сетей является устройство обмена на два входа, два выхода, выполняющее четыре функции: прямое, перекрестное, верхнее общее и нижнее общее соединения. Для сети, соединяющей N входов с /выходами (Nявляется степенью числа 2), число каскадов равно log2W, а число устройств обмена (N/2)\og2N. При этом задержка в сети равна 0(\og2N). Сложность аппаратуры, определяемая как 0(log2 АО, гораздо меньше, чем О (N2) в сети коммутаторов. Так как сети имеют отличную от ненулевой вероятность блокировки, некоторые из возможных распределений источников и приемников не приводят к полному распределению ресурсов. Централизованный планировщик должен проверить все возможные из запрошенных соединения для распределения наибольшего количества ресурсов. Предположим, что х процессоров выдают запросы и свободны у ресурсов. Планировщик должен проверить максимум ($)yl (при х>у) или (£)х! (при у>х) соединений, чтобы най- ти лучшее. Может быть использовано близкое к оптимальному эвристическое решение [19], но оно применимо только при малыхх иу. В противоположность этому децентрализованный алгоритм распределения допускает параллельную маршрутизацию всех запросов. При этом затраты на распределение пропорциональны задержке в сети О (\og2N) и не зависят от числа запрашивающих процессоров. Децентрализованный алгоритм реализуется распределением функций маршрутизации по сети соединений и поэтому централизованного управления нет. Каждое устройство обмена может разрешать конфликты и маршрутизировать запросы к соответствующим приемникам. Если запрос заблокирован, он отсылается обратно к устройству обмена в предыдущем каскаде. Маршрутизация, таким образом, выполняется динамически, и все устройства обмена работают независимо. Децентрализованный алгоритм проиллюстрирован рис. 25.11 на примере сети "Омега" размером 8X8. Предположим, что имеются ресурсы R0, Ri, R4, Rs и информация о состоянии поступает в процессоры. Цифры, проставленные на портах ввода-вывода, представляют передаваемую и принимаемую информацию о состоянии. Предположим, что процессоры Р0, Р3, Р4 и Р5 запрашивают по одному ресурсу каждый и запросы в сеть передаются по поступлении новой информации о состоянии одновременно. В каскаде О конфликтов нет. В каскаде 1 устройство В\9\ принимает два запроса. Так как только один терминал вывода приводит к свободным ресурсам, запрос, поступающий с устройства £0,з, отклоняется. Далее этот запрос находит другой маршрут через £м и £2,2 и Rs. В данном примере каждый из запросов должен проходить в среднем через 3,5 устройства обмена до того, как 2 В Каскад 1
о 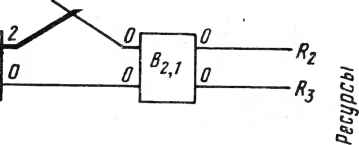
Рис. 25.11. Пример сети "Омега" с четырьмя запрашивающими процессорами и четырьмя свободными ресурсами (25 % всех запросов блокируются и направляются обратно; 100 %-ное распределение ресурсов; средняя задержка равна 3,5) : -прямой путь;----обратный путь будет найден свободный ресурс. В целях упрощения изменение состояния при поступлении новых запросов на рисунке не показано. Рассмотренная здесь сеть распределения ресурсов является обобщенным вариантом адресных сетей соединений с тэгами маршрутизации. Адресная сеть - сеть распределения ресурсов, соединяющая процессоры и множество типов ресурсов с одним ресурсом каждого типа. В режиме разделения ресурсов имеется множество ресурсов каждого типа. Такая сеть распределения ресурсов имеет регулярную структуру, пригодную для реализации на СБИС. 25.6. ЗАКЛЮЧЕНИЕ Выделение признаков и классификация образов - первые кандидаты на возможную реализацию в СБИС. Дня реализации в СБИС были предложены [8] метод выделения признаков Фоли-Сэммона [5] и фишеровский линейный классификатор. Другие методы, такие как метод, основанный на использовании собственных векторов для выделения признаков, и метод байесовских квадратических дискриминантных функций, также должны быть реализуемы на СБИС-оборудовании. Весьма желательно создать вычислительные структуры на СБИС для сглаживания, регистрации, выделения контура, сегментации, анализа текстуры, многоэтапного выделения признаков, распознавания синтаксических форм, обработки и графического анализа, управления базой данных изображения и других операций. Потенциальный выигрыш состоит не только в увеличении скорости, но и в повышении надежности и экономичности. Анализ изображения и управление базой данных изображения являются неотделимыми функциями эффективной графической информационной системы. Интегрированный системный подход обеспечивается слиянием технологии СБИС с разнообразными методами параллельной обработки. Ключевой проблемой разработки специализированных машин для обработки, распознавания и управления базой данных изображения является экономическая эффективность. Для реализации интегрированных вычислительных систем анализа и поиска изображений предлагаем ряд важных исследовательских проектов: 1)разработка систематической методологии реализации алгоритмов распознавания образов и обработки изображений в виде СБИС-аппаратуры [3,6-9,15,20,21]; 2)разработка кристаллов СБИС для описания, манипуляции и исследования изображений [2,11,13,17]; 3)разработка машин баз данных изображений с учетом вопросов как структуры баз данных, так и стратегии управления [4, 16, 22]; 4)разработка сетей распределения ресурсов для процессорных систем с общим пулом ресурсов СБИС [1, 18,19]; 5)исследование возможности использования понятия потока данных при проектировании СБИС-систем распознавания образов, обработки изображений и искусственного интеллекта [1,7, 23]; 6)объединение СБИС-систем анализа изображений со СБИС-системами обработки речи и естественных языков [10, 23, 24]. СПИСОК ЛИТЕРАТУРЫ [I]F. A. Briggs, К. S. Fu, К. Hwang, and В. W- Wah, "PljMPS Architecture for Pattern Analysis and Image Database Management" IEEE T*rans. Comput., Oct. 1982, pp. 969-982. [2] S. K. Chang, J. Reuss, and В. H. McCormi**> "Design Considerations of a Pictorial Database System," Intl. J. Policy Anal. Inf. Syft., 7(2):49- 70 (Jan. 1978). [3] К. H. Chu and K. S. Fu, "VLSI Architecture for Highspeed Recognition of General Context-Free Languages and Finite-State Languages," Proc. 9th Intl. Symp. Comput. Arch., Austin, Tex., Apr. 1982, pp. 43-49. [4] T. DeWitt, "DIRECT: A Multiprocessor Database Machine," IEEE Trans. Comput., 1979, pp. 395-406. [5] D. H. Foley and J. W. Sammon, "An Optimal Set of Discriminant Vectors," IEEE Trans. Comput., Mar. 1975, pp. 281-289. [6] M. J. Foster and H. T. Kung, "The Design of Special-Impose VLSI Chips," Comput. Mag., Jan. 1980, pp. 26-40. [7] K. Hwang and F. A. Briggs, Computer Arch,itectures № Parallel Processing, McGraw-Hill, New York (in press to appear). [8] K. Hwang and S. P. Su, "VLSI Architectures for Mature Extraction and Pattern Classification," J. Comput. Graphics Image process., (accepted to appear in 1983). [9] K. Hwang and Y. H. Cheng, "Partitioned Matrix Algorithms for VLSI Arithmetic Systems," IEEE Trans. Comput., Dec. 1982, ]PP- 1215-124. [10] K. Hwang and K. S. Fu, "Integrated Computer Architectures for Pattern Analysis and Image Database Management," Computer, №n-1983, pp, 51-61. [II]M. Опое, K. Preston, and A. Rosenfeld, «e<*s-» Reaine/Parallel Computing: Image Analysis, Plenum Press, New York, 1981. [12] K. Preston, Jr., and L. Uhr, eds., Multicomptuters an& 1*Паде Processing, Academic Press, New York, 1982. [13] N. S. Chang and K. S. Fu, "Picture Query 1 Languages for Pictorial Database Systems," Computer, 14, Nov. 1981. [14] K. S. Fu, Syntactic Pattern Recognition aW* APPlic(4icns, Prentice-Hall, Englewood Cliffs, NJ., 1982. [15] E. E. Swartzlander, "VLSI Architecture," in* D. F. Barbe,ed., Very Large Scale Integration (VLSI): Fundamentals and Applications** sPrin8erVerlag, New York, 1980. [16] B. W. Wah and S. B. Yao, "DIALOG-A Distributed Processor Organization for Database Machines," AFIPS Conf. Proc., Vc°l- 49,1980, NX, pp. 243-253. [17] M. Yamamura, N. Kamibayashi, and T. Ichirikawa, *Otgaiization of an Image Database Manipulation System," Proc. Workshop C(PmPut- ArcK fir PAIDM, Hot Springs, Va., 1981, pp. 236-241. [18] D. W. L. Yen and A. V. Kulkami, "The ESSL Systolk Processor for Signal and Image Processing," Proc. Workshop Comput. АгсФ- for РА1Ш, Hot Springs, Va., 1981, pp. 265-272. [19] B. W. Wah, "A Comparative Study of Resource Shrg on Multiprocessors," IEEE Trans. Comput., Aug. 1984. [20] H. H. Liu and K. S. Fu, "VLSI Systolic Propcessor for Seismic Classification," Proc. 1983 Intl. Symp. VLSI Tech. Syst. Appl, Taipei* Taiwa цаг. 3 1983. [21] Y. T. Chiang and K. S. Fu, "A VLSI Architecture for Fast Context-Free Language Recognition (Earleys Algorithm)," Proc. 3rd Intl. Conf. Distributed Comput. Syst., Oct. 1982. [22] K. Yamaguchi and T. L. Kunii, "PICCOLO Logic for a Picture Database Computer and Its Implementation," IEEE Trans. Comput., Oct. 1982, pp. 983-996. [23] K. Hwang, "Computer Architectures for Image Processing," (Guest Editors Introduction), Computer, Jan. 1983, pp. 10-13. [24] K. S. Fu, ed., Applications of Pattern Recognition, CRC Press, Boca Raton, Fla., 1982. 26 ОБРАБОТКА СИГНАЛОВ ПРИ ВЫСОКОЙ СКОРОСТИ ПОСТУПЛЕНИЯ ДАННЫХ: ИСПОЛЬЗОВАНИЕ СИСТЕМ С ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРОЙ И ВЫСОКИМИ ТАКТОВЫМИ ЧАСТОТАМИ Б. Гилберт, Т. Кинтер, Д. Шваб, Б. Наусед, Л. Крюгер, В. Ван Нурден1, Р. Зукка2 26.1. ВВЕДЕНИЕ В данной главе исследуются методы использования появившейся недавно технологии изготовления сверхбольших интегральных схем (одна интегральная схема может содержать более 10000 логических элементов) для решения сложных задач обработки сигналов. В предлагаемой главе основное внимание будет уделено узкоспециализированному классу задач обработки сигналов, а именно той незначительной части этих задач, в которой на вход цифровою процессора в реальном масштабе времени поступает один поток необработанных данных с очень большой шириной полосы частот. Этот насыщенный поток данных должен быть обработан, по крайней мере, устройством предварительной обработки процессора сигналов со скоростью, равной или превышающей скорость их поступления; на последующих стадиях обработки возможны разделение единого высокоскоростного потока данных на серию подпотоков, имеющих меньшую скорость, и организация их параллельной обработки. Наша лаборатория с начала 70-х годов исследует возможные способы решения подобных задач, характеризуемых высокой скоростью поступления данных. Был проведен сравнительный анализ выдвигаемых при этом требований с возможностями как технологии кремниевых СБИС, так и других потенциально перспективных для этих задач технологий. Развитие технологии изготовления цифровых ИС общего, а частично и военного назначения было направлено на формирование физических струк- 1May о Foundation, Рочестер, Миннесота. 2Фирма Rockwell International, Таузанд-Окс, Калифорния. 0 ... 69 70 71 72 73 74 75 ... 78 |












