Раздел: Документация
0 ... 50 51 52 53 54 55 56 ... 78 чения дополнительных процессоров. Эти контрольные задачи были тщательно отобраны с целью выявления внутренних сложностей, касающихся численного анализа, управления данными и структуры программ, которые обычно встречаются при использовании обычных вычислительных машин для произвольной матричной обработки. Для анализа разработки использовались следующие контрольные задачи: Скалярное произведение двух массивов при: 32-разрядном накоплении 16-разрядных чисел с блочной плавающей запятой, 48-разрядном накоплении 16-разрядных чисел с блочной плавающей запятой. Операции с плавающей запятой: умножение при 32-разрядной мантиссе и 16-разрядном порядке, сложение при 32-разрядной мантиссе и 16-разрядном порядке. Операции БПФ: прореживание, общий проход, первый проход. Алгоритмы фильтрации: с одним вещественным полюсом, с двумя вещественными полюсами, и усиления с комплексно-сопряженными парами полюсов и нулей. Этот набор задач был запрограммирован в микрокомандах и использован для проверки соответствия архитектуры поставленным целям по обеспечению эффективности. Для эффективной реализации известного в настоящее время семейства алгоритмов LPC выработан определенный архитектурный стиль организации внутренних связей регистров, сумматоров, умножителей и матричной памяти. Однако при рассмотрении БПФ, операций с числами в комплексной форме, г
и операций обращения матриц для выполнения разработки нам потребуется реализовать более сложные связи и некоторое число вспомогательных регистров. Времена выполнения для запрограммированных контрольных задач приведены в табл. 18.1. 18.3. ХАРАКТЕРИСТИКИ МАТРИЧНОГО ПРОЦЕССОРА Простая схема, достаточная для демонстрации архитектуры, показана на рис. 18.1. В системе используется арифметическое устройство обработки (кристалл АУО), два матричных запоминающих устройства (X и Y) , разделенная память данных (DR и DL) , которая должна использоваться совместно с центральным вычислителем, а также секция управления матричного процессора, память микропрограмм (Р) , приемопередатчики и конвейерные регистры (DX и DY). В АУО реализованы следующие средства: 1)три 16-разрядных сумматора и четыре накапливающих регистра, соединенные таким образом, чтобы они образовали четырехмагистральную структуру ; 2)конвейерный умножитель на 17 X 17 разрядов со знаком в 17-разряде; выход умножителя подключен к трем 16-разрядным сумматорам; Управление вводом-выводом дД---jftv"- Данные ввода-вывода ХА  Арифметическое устройство обработки Рис. 18.1. Структурная схема матричного процессора 3)форматирующее устройство для вычисления векторов с плавающей запятой при масштабировании данных в процессе вычислений; 4)специальное оборудование для повышения эффективности арифметических операций с плавающей запятой; 5)средства адресации матриц по строкам или столбцам одновременно для памяти X и Y; 6)устройство прямой адресации двумерных окон на девять точек, центрированных относительно индекса матрицы; 7)аппаратный реверсор на 16 разрядов для прореживания; 8)четыре локальных вспомогательных регистра; 9)средства защиты внешних шин X, Y и R внутри кристалла АУО. 18.4. ОСНОВНЫЕ ХАРАКТЕРИСТИКИ АРИФМЕТИЧЕСКОГО УСТРОЙСТВА ОБРАБОТКИ На основе кристалла АУО можно строить вычислительные системы буквально любого из известных на сегодня типов, не используя никаких других арифметических средств, кроме предоставляемых АУО. Это действительно универсальное устройство, а не часть специализированной системы на одном кристалле. В этой главе покажем некоторые из способов, которыми данный кристалл может быть использован как универсальный компонент систем самого разного назначения и возможностей. Небольшие микропроцессорные вычислительные системы дают очень хорошие возможности по подготовке программ и решению несложных задач. Однако, когда требуются сложные научные расчеты, эти вычислительные мощности оказываются недостаточными. Значительно увеличить производительность можно при использовании АУО в качестве ускорителя. Придерживаясь одноадресного формата команд, что упрощает написание компилятора, мы предлагаем использовать для построения микрокоманд АУО небольшое ПЗУ перекодировки, которое приспосабливает арифметические операции к типичным операциям соответствующих мини-ЭВМ. Конечно, большинство полученных для данного типа процессора микроопераций будут холостыми, поэтому следует предусмотреть аппаратные холостые команды с мультиплексированием полей, которые обеспечат управление отдельными арифметическими операциями. Специализированные вычислители ориентированы на выполнение частного, алгоритма при минимуме оборудования. Ввиду тесной связи их структуры с конкретным алгоритмом в каждом частном случае необходим отдельный проект. Следовательно, простота выполнения такого проекта является важу ным фактором, влияющим на экономическую эффективность таких систем. Однако при наличии современных 16-разрядных микропроцессоров, кристалла АУО и многоразрядных ОЗУ такой проект может быть реализован простым объединением унифицированных компонентов в системы простой конфигурации. Очевидно, что такой модульный подход приведет к автоматизированному проектированию по принципу "крупномодульного проектирования" для разработки проектов по требованиям пользователя. Матричные процессоры можно рассматривать на нескольких уровнях производительности. На нижнем уровне производительности мы видим системы с небольшим набором присоединяемой памяти, управляемые готовыми устройствами управления. Для сокращения числа кристаллов памяти используется последовательное считывание микрокоманд из памяти, а также последовательное считывание векторов из памяти и их запись в память. При среднем уровне производительности матричных процессоров будет использоваться полный набор кристаллов микропрограммной памяти и число их определяется тем, сколько слов необходимо иметь в каждом из следу-ющих модулей памяти: X, Y - память векторов, РН - ПЗУ микрокоманд, PS - ОЗУ микрокоманд, D - системная память. Высокопроизводительные матричные процессоры могут быть получены при использовании нескольких кристаллов АУО для обеспечения высокого уровня параллелизма арифметических операций и увеличения их точности. Разумеется, требуется еще большее число кристаллов памяти для обеспечения времени доступа, соответствующего АУО повышенной производительности. Для обеспечения сверхвысокого уровня производительности мы предлагаем микросеть матричных процессоров, где каждый узел имеет универсальное управлениеч локальную операционную систему и микросети связи в многосвязной структуре. Необходима, конечно, и глобальная операционная система для управления заданиями и ресурсами. Реальная возможность создания такой системы ограничивается только уровнем знаний в области организации системы и программирования многопроцессорных компиляторов с переменным составом процессоров во время выполнения. 18.5. КРИСТАЛЛ АРИФМЕТИЧЕСКОГО УСТРОЙСТВА ОБРАБОТКИ Кристалл арифметического устройства обработки состоит из трех секций: 1) арифметического процессора данных, 2) двух одинаковых контроллеров адреса матричной памяти и 3) необходимых управляющих логических устройств . Арифметический процессор данных выполняет всю арифметическую обработку элементов матрицы и имеет небольшую память для хранения промежуточных результатов и параметров. Контроллеры адреса вычисляют адреса массива, относящихся к ячейкам памяти X и Y. Управляющие логические устройства обеспечивают всю синхронизацию и управление АУО при длительности сигналов микрокоманд 20 не, вырабатывают два синхросигнала и два специальных сигнала управления. Кристалл АУО (рис. 18.2) содержит 100 выводов. Выводы имеют следующее обозначение: Х0 - X15 - входы-выходы шины X, Y0 - Y15 - входы-выходы шины Y, ХАО - ХА15 - выходы адреса памяти X, YA0 - А15 - выходы адреса памяти Y, 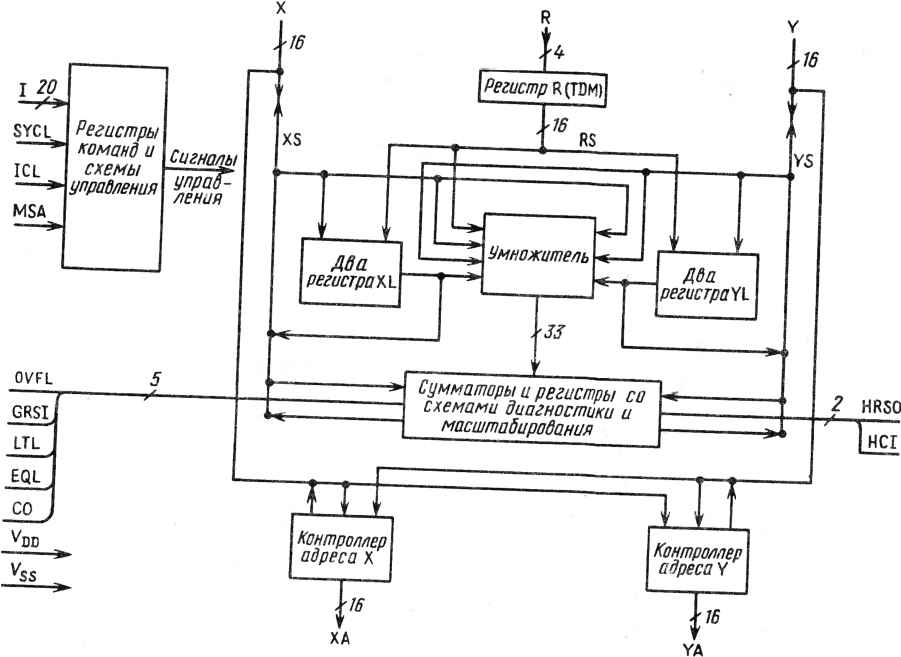 Рис. 18.2. Арифметическое устройство обработки Ю-119 -входы микрокоманды; используется четырехтактный системный цикл синхронизации, -вход синхронизации системы; номинал синхронизации - 4 МГц, проектируется повысить до 5 МГц, -четырехфазный синхровход для микрокоманд и данных R; номинал частоты синхронизации - 16 МГц; проектируется повысить до 20 МГц, -входы шины данных R; используются четырежды за один цикл синхронизации системы, -выходы проверки данных, -входы-выходы управления параллельной работой нескольких АУО, -выводы питания. Приборы будут выполнены в корпусах с матричным расположением выводов. Совмещение контроллеров адреса X и Y с арифметическим устройством потребовало изоляции шин XS от шин X арифметического устройства. Аналогично имеются шины YS, изолированные от шин Y. Таким образом, работа с внешней памятью (связанная с использованием контроллеров адреса) может осуществляться в течение обработки данных АУО при расширении шин X и Y (XS и YS) . SYCL ICL RI EQL, LTL MS A, OVFL, GRSI, HRSO VSS,VDD 18.5.1. Общая архитектура Архитектура АУО показана на рис. 18.3, а коды микрокоманд -на рис. 18.4. Основными элементами процессора обработки данных являются: 1)конвейерный (17 X 17)-разрядный умножитель с регистрами МА и MB, которые вырабатывают 33-разрядный результат, запоминаемый в двух регистрах (MPL и MPR) . Регистр MPL содержит 17 старших разрядов, a MPR - 16 младших разрядов результата. Эта 33-разрядная пара регистров обозначается как MP; 2)три 16-разрядных сумматора: F, G, и Н. Эти сумматоры независимы, но могут объединяться для получения 32- или 48-разрядной точности; 3)две внутренние шины: X и Y; 4)четыре 16-разрядных аккумулятора: Т, U, V и W. Аккумуляторы U и V могут загружаться из двух сумматоров, а Т и W - из одного сумматора с шин XS или YS; 5)четыре локальных запоминающих регистра: XLO, XL1, YLO, YL1; 6)независимая входная шина (R) : с нее могут загружаться локальные регистры или умножитель. Кроме того, арифметическое устройство содержит средства для организации сдвигов, масштабирования, нормализации, поразрядного реверсирования и проверки условий сумматоров G и Н. Большинство элементов соединено с одной или двумя внутренними шинами XS(YS) по входам и (или) выходам. Имеются соединения с умножителем и сумматорами помимо шин. В частности, входы умножителя подключены к локальным регистрам XLi и YLi (i = 0 или 1). Сумматоры имеют входы А, соединенные с выходными регистрами умножителя MPL и (или) MPR, и входы В, соединенные с группой аккумуляторов ; ни один из входов В не соединен с шинами XS (YS). Каждый из сумматоров может непосредственно загружать два конкретных аккумулятора; сумматор G может также выдавать информацию на шину YS. Структура соединений такова, что сумматоры и аккумуляторы могут использоваться для обеспечения внутреннего конвейера, содержащего до четырех ступеней и загружаемого с одной из шин, а разгружаемого на другую. Также возможно обменивать содержимое аккумуляторов U и V за такт через сумматоры G и Н без использования шин или промежуточных регистров. В сумматорах реализовано два типа сдвигов. 1.Сдвиг на один разряд вправо (RS) содержимого на выходе сумматора G с передачей в аккумулятор U или сумматора Н с передачей в аккумулятор V, или конкатенации GH с передачей в UV; сдвиг распространяется на все выходы сумматора G (и (или) сумматора Н), включая выходы на шину YS. 2.Условный сдвиг на один разряд вправо (CS) содержимого сумматора G с передачей в U или сумматоров GH с передачей в UV; сдвиг, если это разрешено, производится при переполнении в сумматоре. Сдвинутый результат в этом случае является откорректированным значением величины, а признак переполнения показывает, что был произведен сдвиг. На выходе регистра LGCO (контакт СО) будет бит переполнения всегда, когда требуется условный сдвиг. 0 ... 50 51 52 53 54 55 56 ... 78 |
||||||||||||||||||||||||||||||||||||||












