Раздел: Документация
0 ... 62 63 64 65 66 67 68 ... 78 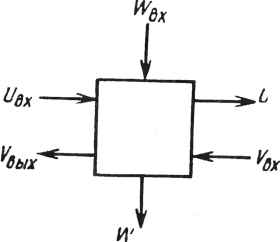 дых увых~ vBx Вых где s - знак, используемый при сложении. Им может быть знак +, -, или он может меняться. Операнды представляются в формате с плавающей запятой. Значительные усилия были направлены на обеспечение коммутационных функций и увеличение числа внутренних регистров для повышения гибкости архитектуры ВСК. Для выполнения арифметических операций над комплексными величина-ми могут быть построены комбинированные ячейки. Здесь представлены две разработки Кунга: комплексная ячейка, содержащая два ВСК: -ос а .J5 Ji а ос Р fl 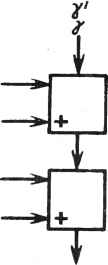 и другая - на четырех кристаллах, в которой один из операндов постоянен Г а 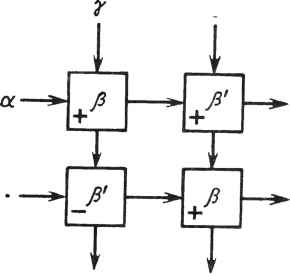 Это внутренняя ячейка для комплексной матрицы обратного хода. На рис. 22.10 представлена схема ячейки для комплексного вращения Гивенса, содержащая шесть ВСК. Имеются две двухкристальные ячейки комплексного умно жителя-сумматора, одна из них для вычисления другая - для су, а также две однокристальные ячейки для вещественно-комплексного умножителя-сумматора; одна для вычисления ох и дру- 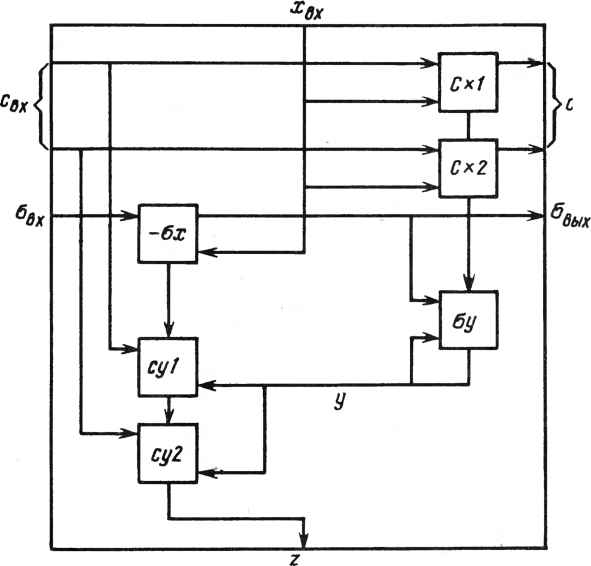 вых Вых Рис. 22.10. Комплексная ячейка Гивенса гая - для оу. Комплексные величины представлены в одном из форматов, рассмотренных ранее. Новые операнды могут поступать в ячейку в каждом втором такте. Задержка в тракте x - z составляет три такта, а в трактах свх ~ свых и °вх ~ °вых ~ всего опин такт- К сожалению, ограниченный объем раздела не позволяет обсудить детально способы реализации граничных ячеек. Необходим еще один ВСК - кристалл, характеризуемый наличием еще более быстродействующих логических элементов или большим внутренним параллелизмом, который мог бы обеспечить выполнение операций деления, извлечения корня и его обратной величины за один цикл. Этот кристалл мог бы использоваться наряду с ВСК при создании конвейеризованной граничной ячейки для выполнения операций QU, обратного решения или LU с достаточной для матрицы производительностью. Граничные ячейки обычно характеризуются большей задержкой, чем внутренние. В трапецеидальной QU-матрице эта повышенная задержка граничной ячейки рассинхронизирует процессы, если не обеспечены приемлемые задержки в линиях связи между ячейками. К счастью, эти задержки необходимы только в левой треугольной части матричной структуры. На рис. 22.11 приведен соответствующий пример. В нем задержка граничных ячеек составляет 5 единиц, внутренних - 4 единицы, хотя задержка при передаче слева направо равна 1. Для каждой ячейки указано время поступления операнда. Задержки обозначены ромбами; они задерживают данные на четыре цикла. G> 6 11 15 72 16 20 24 17 21 25 Рис. 22.11. Влияние задержки граничных ячеек Их назначением является выравнивание задержек различных трактов в матрице. В матричном процессоре размером pXq потребуются ячейки с задержкой р(р - 1)/2. Эти задержки влияют на общую задержку тракта и на задержку в тракте от входа к выходу (это уже не параллелограмм). Однако снижения пропускной способности не происходит. СПИСОК ЛИТЕРАТУРЫ [1] A. Bojanczyk, R. P. Brent, and Н. Т. Kung, "Numerically Stable Solution of Dense Systems of Linear Equations Using Mesh-connected Processors," Siam Jour, on Scientific and Statistical Computing, 5:1, pp. 95-104, 1984. [2] W. M. Gentleman and H. T. Kung, "Matrix Triangularization by Systolic Arrays," Real Time Signal Processing IV, SPIE, Vol. 298, Society of Photo-optical Instrumentation Engineers, Bellingham, Wash., 1981. [3] D. E. Heller and I. C. F. Ipsen, "Systolic Networks for Orthogonal Decompositions." Siam Jour, on Scientific and Statistical Computing, 4:2, pp. 261-269, 1983. [4] R. Schreiber, "Systolic Arrays for Eigenvalue Computation," Real Time Signal Processing W SbPIf982°1 341 So€iety °f Pnoto-°Ptical Instrumentation Engineers, Bellingham, [5] H. J. Whitehouse and J. M. Speiser, "Sonar Applications of Systolic Array Technology," IEEE EASCON Proc, 1981. 23 МНОГОПРОЦЕССОРНЫЕ ПАРАЛЛЕЛЬНЫЕ СТРУКТУРЫ, КОНВЕЙЕРЫ И ПИРАМИДЫ ДЛЯ ВОСПРИЯТИЯ ОБРАЗОВ Л. Ур1 23.1. ВВЕДЕНИЕ: ЗНАЧИТЕЛЬНОЕ УВЕЛИЧЕНИЕ МОЩНОСТИ И ПРОИЗВОДИТЕЛЬНОСТИ ПРИ ИСПОЛЬЗОВАНИИ СБИС Универсальные приборы, эквивалентные по значению транзистору, которые создаются на тонких кремниевых пластинках СБИС, в настоящее время так миниатюрны и дешевы, что настал момент, когда чрезвычайно большое число процессоров может быть объединено в единую сеть. В 1978 г. 100 ООО элементов было успешно интегрировано в ЗУПВ объемом 64 Кбит. В 1981 г. фирма Hewlett-Packard объявила о создании микропроцессорного кристалла, содержащего 450ООО элементов. Мы явились свидетелями удвоения степени интеграции приблизительно каждые 12-18 мес. в течение последних 10-20 лет, и весьма вероятно, что такое положение будет сохраняться еще от 10 до 20 лет. Следовательно, многопроцессорные компьютеры "среднего класса" с числом кристаллов от нескольких тысяч и до миллиона, или даже 10 миллионов элементов в каждом кристалле, скоро станут реальностью. Это означает, что отдельный компьютер может содержать 104Х Х107 = 101! элементов. Такие микропроцессорные системы могут быть очень успешно использованы для штурма чрезвычайно больших проблем, примером которых является моделирование в трех измерениях атмосферных масс для прогноза погоды, моделирование трехмерных зон земной коры для изучения таких явлений, как землетрясения, моделирование обширных сетей нейронов, составляющих мозг человека, и очень большой набор преобразований, необходимых для восприятия сложного поведения пространственных объектов. Для таких компьютеров обработка изображений и восприятие образов станут основными областями применения, так как они выдвигают чрезвычайно серьезные проблемы информационной обработки, решение которых требует очень больших и быстродействующих микромодульных компьютеров с высоким параллелизмом. При очень большом потоке исходных данных об изображении, растрированном на 5122, 10242 и более элементов, массив элементов растра может быть весьма эффективно обработан с помощью локальных операций, в процессе которых "рассматривается" каждый элемент, а также его соседи. Такое локальное операционное "окно" может быть высокоэффективно реализовано на соответствующим образом спроектированном параллельном процессоре. При этом производительность может быть повышена на много порядков по сравнению с производительностью 1 Висконсинский университет, Мадисон, Висконсин. ЦП Ввод- Вывод Память о) Память ЭВМ -ЭВМ- 6) в) Рис. 23.1. Традиционная однопроцессорная последовательная ЭВМ: а - ЗУ подключено к ЦП (содержащему и процессор, и контроллер) ; в свою очередь, они связаны с устройствами ввода и вывода (часто через регистры R ); б - процессор подключен к ЗУГТВ относительно большой емкости (ввод и вывод не показаны, но имеются) ; в - отдельная ЭВМ (ввод и вывод подразумеваются) и ЭВМ с вводом и выводом, показанными стрелками обычного последовательного процессора. Это впервые сделает возможным создание программ обработки изображений и восприятия образов, способных распознавать сложные образы реального мира при их движении в реальном масштабе времени, т. е. в отрезке 30 мс или менее на кадр изображения. 23.2.ТРАДИЦИОННЫЕ ОДНОПРОЦЕССОРНЫЕ ПОСЛЕДОВАТЕЛЬНЫЕ ЭВМ И МНОГОПРОЦЕССОРНЫЕ СЕТИ Обычная "последовательная универсальная ЭВМ" (рис. 23.1) строится, как правило, посредством подключения быстродействующей памяти к единственному центральному процессору (ЦП), который выбирает команды из памяти, декодирует каждую из них, выбирает данные (в соответствии с предписанием в команде), хранящиеся в указанных ячейках памяти, выполняет указанные операции и запоминает результаты в предписанных ячейках. Кроме того, к системе должны быть подключены устройства ввода и вывода. На рис. 23.1 приведено несколько вариантов представления такой системы. 23.3.КОНВЕЙЕРНЫЕ СИСТЕМЫ КОМПЬЮТЕРОВ (ИЛИ ПРОЦЕССОРОВ) Было построено несколько конвейерных систем, и большинство из них - в духе заводских сборочных линий. Каждый процессор в системе многократно выполняет одну и ту же команду над последовательностью данных, проходящих через систему. Это значит, что если одна и та же последовательность команд должна выполняться над большим числом различных блоков данных (случай, когда данные, составляющие массив, должны обрабатываться параллельно подобно выполнению вложенных циклов FOR, как в рассматриваемых примерах прикладных задач), может быть построена конвейерная система длиной во всю последовательность команд и данные (например, информация, хранящаяся в ячейках матрицы) могут быть пропущены через процессоры системы Ш -IJN (рис. 23.2). 398 Устройства „Устройство Ввода +П1+П2+П3-*П.*ПН-+ в"ыбода Рис. 23.2. Конвейер из N процессоров, через которые проходят данные. В такте 1 процессор Ш будет выполнять первую команду над первым блоком данных. В такте 2 процессор П2 будет выполнять вторую команду над первым блоком данных, а Ш - первую команду над вторым блоком данных и т. д. Если в конвейере имеется 7Vпроцессоров, программа будет выполняться приблизительно в dN раз быстрее, чем в однопроцессорной ЭВМ. (d - коэффициент, учитывающий, что нет необходимости в выборке и декодировании следующей команды, поскольку каждый процессор осуществляет выборку один раз, а затем многократно повторяет выполнение одной и той же команды.) Наиболее высокопроизводительные из современных "супер-ЭВМ", например Сгау-1 и CDC-255 фирмы Seymour Cray (см. [11]), содержат подобные конвейеры из дюжины или около того очень мощных и дорогостоящих процессоров для выполнения векторных операций над массивами данных. Машина PICAP [12] содержит конвейер из процессоров, специально спроектированный для реализации окна размером 3X3, в котором выполняется любая логическая или арифметическая операция, операндами которой являются центральная ячейка окна, а также восемь соседних ячеек по выбору программиста. Наиболее длинный из построенных к настоящему времени конвейеров - конвейер многопроцессорной системы Cytocomputer [22], специализированный на выполнение операций обработки изображений. В его состав входят процессоры двух типов, один из которых предназначен для вычисления булевых функций над содержимым центральной и восьми соседних с ней ячеек, а другой - для вычисления арифметических функций над 3-разрядными величинами в шкале серого, хранящимися также в девяти ячейках окна. Каждый из процессоров машины Cytocomputer гораздо проще и меньше, чем в ЭВМ Сгау-1, но их общее число составляет 113. Используя новые кристаллы СБИС (один процессор в кристалле), проектируемые на будущее системы планируется построить из еще большего числа процессоров, которые могут быть объединены в конвейеры (теоретически произвольной длины [23]). 23.4. МАТРИЧНЫЕ СТРУКТУРЫ ИЗ ОЧЕНЬ БОЛЬШОГО ЧИСЛА ПРОСТЫХ ПРОЦЕССОРОВ В последние годы были построены, или уже завершаются, три очень большие двумерные системы. В их число входят: распределенный матричный процессор размером 64X64 DAP (distributed array processor), спроектированный фирмой ICL [16]; сотовый логический процессор изображений размером 96X96 CLIP4 (cellular logic image processor), разработанный в Лондонском университетском колледже [3]; и большой параллельный процес- 0 ... 62 63 64 65 66 67 68 ... 78 |












